





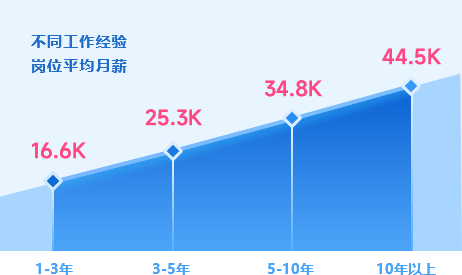
AI人工智能工程師 薪資隨工作經驗持續增長
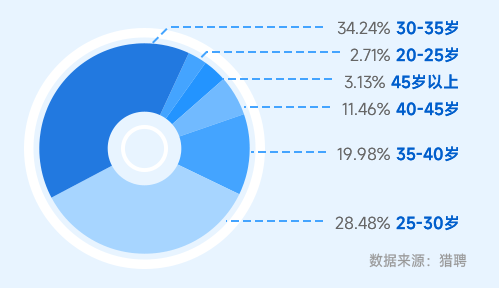
AIGC領域人才超1/3大于35歲 發展路徑長
傳智教育(股票代碼 003032)旗下高端IT教育品牌

人工智能開發




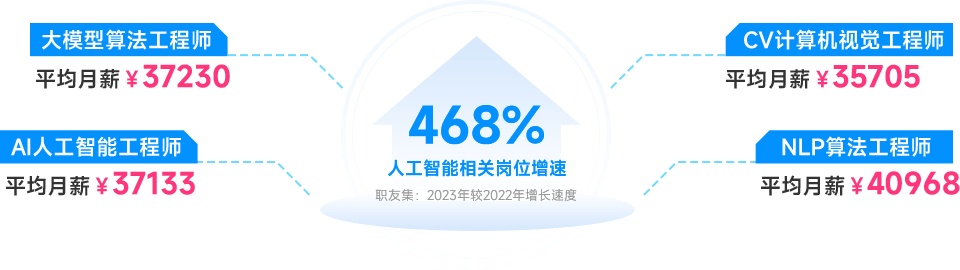
大模型開發工程師、數據挖掘工程師、AIGC算法工程師、大模型Agent工程師、CV計算機視覺工程師、Prompt工程師、大語言模型LLM開發工程師、 大模型推理工程師、算法工程師、機器學習工程師、智能語音算法工程師、大模型微調工程師、NLP自然語言處理工程師、多模態工程師


設計、實現和優化大規模深度學習模型,包括數據預處理、模型架構設計、訓練調優、性能優化以及模型部署,以推動AI大模型技術在各種應
通過處理和分析文本數據,實現語言翻譯、情感分析、自動摘要、聊天機器人等功能。使計算機能夠理解和生成人類語言。
通過圖像和視頻分析、物體識別、場景重建等技術,使計算機能夠理解和解釋視覺數據,支持自動化決策和智能系統。
運用機器學習技術,從大量數據中提取有價值的信息,發現數據背后的模式和趨勢,并為決策提供支持。




Python編程 基礎語法數據結構函數面向對象模塊與包裝飾器選代器
數據處理與統計分析 NumpyPandasMatplotlib/Seaborn

機器學習 Scikit-Learn分類算法回歸算法聚類算法特征工程模型選擇
深度學習 Pytorch神經網絡BP神經網絡CNN卷積神經網絡RNN循環神經網絡

文本預處理 文本處理方法文本張量表示文本預料數據分析數據增強方法命名實體識別Word-Embedding
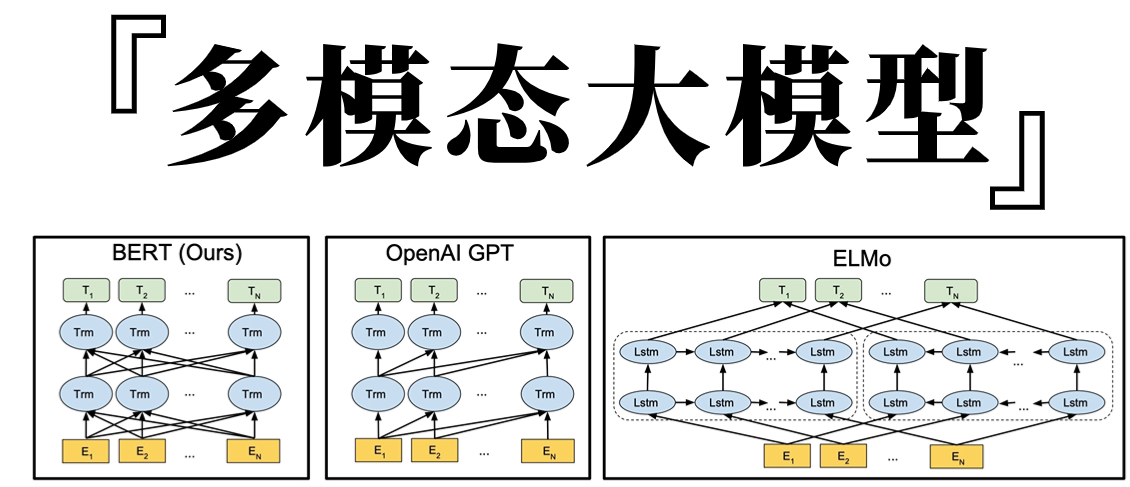
Transformer原理 編碼器解碼器語言模型注意力機制模型超參數
Bert / GPT Bert原理Bert預訓練GPT原理GPT-2ChatGPT
Hive 遷移學習 FastText預訓練模型權重微調
大模型入門 大模型基礎知識主流大模型分類AI應用工具集企業級大模型開發平臺
大模型應用開發 Function Call的原理及實踐大模型Agent原理及實戰
大模型微調開發 提示詞工程實戰【金融】 大模型微調實戰【大健康, 新零售,新媒體】
目標分類 卷積計算方法多通道卷積AlexNetVGG ResNet殘差網絡ImageNet分類
目標檢測 RCNNFPNSSD FasterRCNN非極大抑制NMS
目標分割 全卷積ROI AlignDeepLab MaskRCNN金字塔池化模塊語義分割評價標準
數據結構 棧樹圖數組鏈表哈希表
常見算法 排序查找鏈表算法動態規劃貪心算法
機器學習/深度學習 分類算法面試題回歸算法面試題聚類算法面試題深度學習面試題
NLP/CV專題 Transformer模型原理Bert/GPT面試題
大模型專題 Prompt提示詞LangChain大模型開發工具 模型微調 LoRA/Prefix-Tuning ChatGLM原理與面試題


大模型語言基礎
大模型語言進階
數據處理與統計分析
機器學習
深度學習與NLP自然語言處理基礎
NEWNLP自然語言處理綜合項目
大模型核心開發基礎與項目
企業級大模型平臺開發項目
圖像分析基礎
NEW多模態大模型綜合項目
主要內容
Python基礎語法 | Python數據處理 | 函數 | 文件讀寫 | 異常處理 | 模塊和包
可解決的現實問題
熟練掌握人工智能Python語言,建立編程思維以及面向對象程序設計思想,使學員能夠熟練使用Python技術完成基礎程序編寫。
可掌握的核心能力
1.掌握Python開發環境基本配置
2.掌握運算符、表達式、流程控制語句、數組等的使用
3.掌握字符串的基本操作
4.初步建立面向對象的編程思維
5.熟悉異常捕獲的基本流程及使用方式
6.掌握類和對象的基本使用方式
主要內容
面向對象 | 網絡編程 | 多任務編程 | 高級語法 | Python數據結構
可解決的現實問題
熟練使用Python,掌握人工智能開發必備Python高級語法。
可掌握的核心能力
1.掌握網絡編程技術,能夠實現網絡通訊
2.知道通訊協議原理
3.掌握開發中的多任務編程實現方式
4.知道多進程多線程的原理
主要內容
Linux | MySQL與SQL | Numpy矩陣運算庫 | Pandas數據清洗 | Pandas數據整理 | Pandas數據可視化 | Pandas數據分析項目
可解決的現實問題
掌握SQL及Pandas完成數據分析與可視化操作。
可掌握的核心能力
1.掌握Linux常用命令,為數據開發后續學習打下的良好基礎
2.掌握MySQL數據庫的使用
3.掌握SQL語法
4.掌握使用Python操作數據庫
5.掌握Pandas案例
6.知道繪圖庫使用
7.掌握Pandas數據ETL
8.掌握Pandas數據分析項目流程
主要內容
機器學習簡介 | K近鄰算法 | 線性回歸 | 邏輯回歸 | 決策樹 | 聚類算法 | 集成學習 | 機器學習進階算法 | 用戶畫像案例 | 電商運營數據建模分析案例
可解決的現實問題
掌握機器學習基本概念,利用多場景案例強化機器學習建模。
可掌握的核心能力
1.掌握機器學習算法基本原理
2.掌握使用機器學習模型訓練的基本流程
3.掌握Sklearn等常用機器學習相關開源庫的使用
4.熟練使用機器學習相關算法進行預測分析
主要內容
深度學習基礎 | BP神經網絡 | 經典神經同絡結構(CNN&RNN) | 深度學習多框架對比 | 深度學習正則化和算法優化 | 深度學習Pytorch框架 | NLP任務和開發流程 | 文本預處理 | RNN及變體原理與實戰 | Transformer原理與實戰 | Attention機制原理與實戰 | 傳統序列模型 | 遷移學習實戰
掌握深度學習基礎及神經網絡經典算法;掌握全球熱門的Pytorch技術,完成自然語言處理基礎算法,諸如RNN、LSTM、GRU等技術。
可掌握的核心能力
1.Pytorch工具處理神經網絡涉及的關鍵點
2.掌握神經網絡基礎知識
3.掌握反向傳播原理
4.了解深度學習正則化與算法優化
5.掌握NLP領域前沿的技術解決方案
6.了解NLP應用場景
7.掌握NLP相關知識的原理和實現
8.掌握傳統序列模型的基本原理和使用
9.掌握非序列模型解決文本問題的原理和方案
10.能夠使用Pytorch搭建神經網絡
11.構建基本的語言翻譯系統模型
12.構建基本的文本生成系統模型
13.構建基本的文本分類器模型
14.使用ID-CNN+CRF進行命名實體識別
15.使用FastText進行快速的文本分類
16.勝任多數企業的NLP工程師的職位
主要內容
投滿分文本分類或AI醫生項目 | 泛娛樂關系抽取或知識圖譜項目
可解決的現實問題
1.掌握自然語言處理項目,完成投滿分文本分類或AI醫生項目
2.掌握自然語言處理項目,完成泛娛樂關系抽取或知識圖譜項目
3.掌握運用NLP核心算法解決實際場景關系抽取的問題
可掌握的核心能力
1.抽取式文本摘要解決方案
2.生成式文本摘要解決方案
3.自主訓練詞向量解決方案
4.解碼方案的優化解決方案
5.數據增強優化解決方案
6.大規模快速文本分類解決方案
7.多模型井行預測解決方案
8.分布式模型訓練解決方案
9.多標簽知識圖譜構建解決方案
10.掌握關系抽取任務以及關系抽取的常見場景
11.掌握數據來源、獲取方式以及存儲方式介紹
12.掌握Casrel模型構建:實現關系抽取
主要內容
大語言模型的主要方法與主要架構 | 主流大模型詳解 | 大模型主要微調方法 | 大模型評價指標及模型部署上線
可解決的現實問題
1.掌握大模型核心原理,完成文本摘要或傳智大腦項目
2.掌握大模型應用開發,完成AI Agent項目構建
3.掌握運用大模型核心算法解決實際場景關系抽取的問題
可掌握的核心能力
1.大模型Prompt-Engineering實踐
2.基于Funcation call打造個人專屬助手
3.基于AI Agent實現郵件的自動編寫及發送
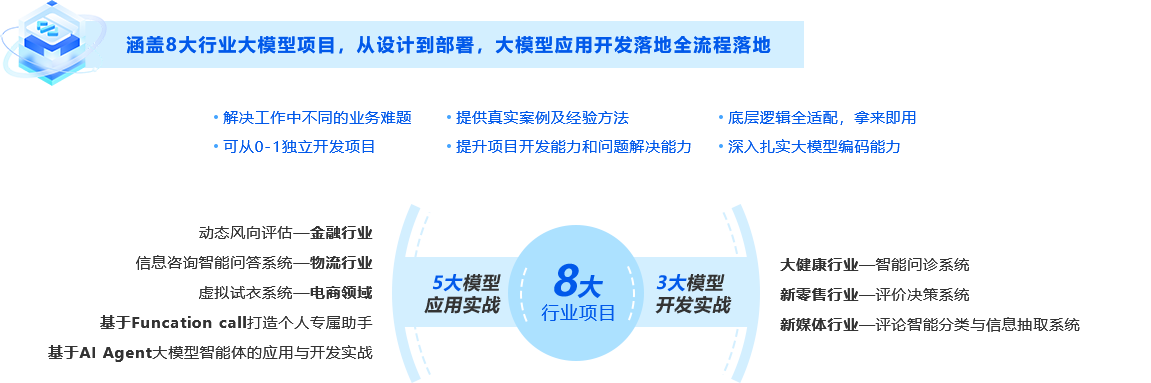
4.物流行業信息咨詢智能問答系統(RAG檢索)
5.基于GPT2模型搭建醫療問診機器人
6.新零售行業決策評價系統
7.新媒體行業評論智能分類與信息抽取系統
主要內容
阿里PAI平臺 | 訊飛星火大模型平臺
可解決的現實問題
1.掌握阿里PAI平臺、百度千帆、訊飛星火等開源大模型平臺使用
2.利用阿里PAI平臺、百度千帆、訊飛星火等開源大模型平臺完成大模型應用與開發
可掌握的核心能力
1.基于阿里PAI平臺的虛擬試衣實戰
2.基于阿里PAI平臺的AI擴圖實戰
3.訊飛星火多風格翻譯機器人實戰
4.基于訊飛大模型定制平臺的金融情感分析項目
主要內容
機器學習核心算法加強 | 深度學習核心算法加強 | 數據結構與算法 | 圖像與視覺處理介紹 | 目標分類和經典CV網絡 | 目標分割和經典CV網絡
1.掌握數據結構與算法,核心機器學習、深度學習面試題,助力高薪就業
2.掌握計算機視覺基礎算法,諸如CNN、殘差網絡、Yolo及SSD
可掌握的核心能力
1.機器學習與深度學習核心算法,NLP經典算法,數據結構算法、Djkstra算法,動態規劃初步,貪心算法原理,多行業人工智能案例剖析
2.經典卷積網絡:LeNet5、AlexNet、 VGG、 Inception、GoogleNlet、殘差網絡、深度學習優化(RCNN、FastRCNN、FasterRCNN、SSD、YOLOM、 YOLOV2、 YOLOV)
主要內容
解決方案列表 | 項目架構及數據采集 | 人臉檢測與跟蹤 | 人臉姿態任務 | 人臉多任務 | Stable Diffusion詳解 | Latte視頻生成(Sora對比)
掌握多模態文生圖項目、人臉支付項目或智慧交通項目
可掌握的核心能力
1.人臉檢測與跟蹤解決方案、人臉姿態任務解決方案、人臉多任務解決方案、人臉識別任務解決方案
2.掌握AIGC的原理、Stable Diffusion模型的構成、訓練策略、視頻生成模型Latte
*課程將會持續更新,更新后所有已報名該課程學員均可免費觀看最新課程內容

1.通過完善系統的知識圖譜知識體系,涵蓋知識表示、知識抽取、知識存儲、知識補全、知識推理相關內容
2.高效的NER實體抽取解決方案,以及RE關系抽取解決方案,涵蓋模型方法和規則方法,雙渠道保證信息抽取的高效性和完備性
3.基于前綴樹和意圖識別,搭建紅蜘蛛醫療機器人,通過訪問Neo4j圖數據庫達成多輪醫療對話的功能
金融關系分析、商品推薦、品牌挖掘、醫療輔助分析
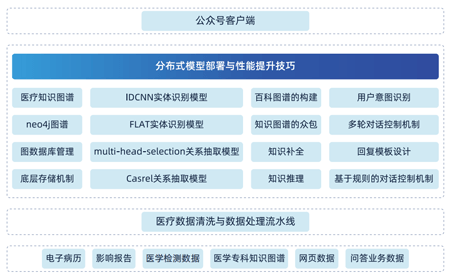
1.項目背景介紹:投滿分項目在今日頭條中的作用,數據集的樣式等。快速實現基于隨機森林的基線模型1.0,和基于FastText的基線模型2.0
2.遷移學習優化:實現基于BERT的遷移學習模型搭建和訓練,并對比模型關鍵指標的提升
3.模型的量化:實現對大型預訓練模型的量化,并對比原始模型與量化模型的差異
4.模型的剪枝:實現對模型的剪枝的操作,包含主流的對特定網絡模塊的剪枝、多參數模塊的剪枝、全局剪枝、用戶自定義剪枝
5.遷移學習微調:包含BERT模型微調、AlBERT模型、GPT2模型、T5模型、Transformer-XL模型、XLNet模型、Electra模型、Reformer模型的詳細介紹,以及消融實驗的介紹
6.模型的知識蒸餾:詳細解析知識蒸餾的原理和意義,并實現知識蒸餾模型的搭建,對比知識蒸餾后的新模型的優異表現,并做詳細的對比測試
金融文本分類、情感分析、醫療報告的自動分類、新聞內容的自動分類
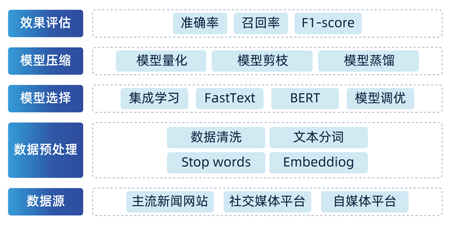
1.項目介紹:理解信息抽取任務以及文本分類的業務意義及應用場景
2.項目流程介紹:完整的實現整個任務的邏輯框架
3.數據預處理:修改數據格式適配大模型訓練、數據張量的轉換等
4.ChatGLM-6B模型解析,LoRA方法講解、P-Tuning方法解析
5.基于ChatGLM-6B+LoRA方法實現模型的訓練和評估
6.基于ChatGLM-6B+P-Tuning方法實現模型的訓練和評估
7.基于Flask框架開發API接口,實現模型線上應用
問答系統、知識圖譜構建、醫療行業信息抽取
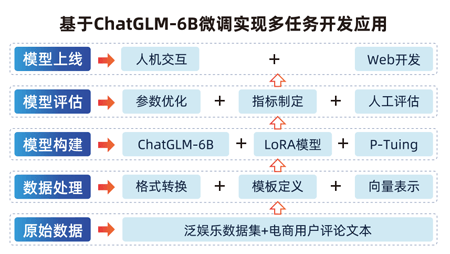
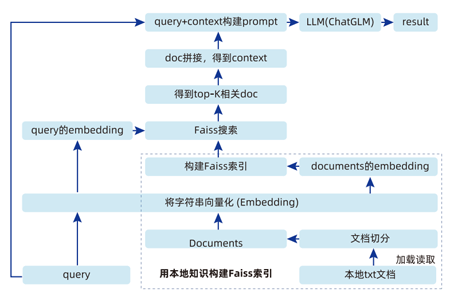
1.項目介紹:理解什么是RAG系統
2.項目流程梳理:從本地知識庫搭建,到知識檢索,模型生成答案等流程介紹
3.數據預處理:本地文檔知識分割、向量、存儲
4.LangChain框架的詳解講解:6大組件應用原理和實現方法
5.基于本地大模型ChatGLM-6B封裝到LangChain框架中
6.實現LangChain+ChatGLM-6B模型的知識問答系統搭建
客戶服務、醫療咨、新聞和媒體
1.項目意義:新零售行業背景和需求
2.BERT模型介紹:架構、預訓練任務、應用場景
3.P-Tuning方法的原理:定義、作用、優點
4.PET方法的原理:定義、作用、優點
5.模型訓練調優:數據清洗、參數選擇、模型訓練
6.模型性能評估:構建評估指標(Precision、Recall)、評估方法(混淆矩陣)
金融行業、供應鏈管理、市場營銷、保險航月、電信行業
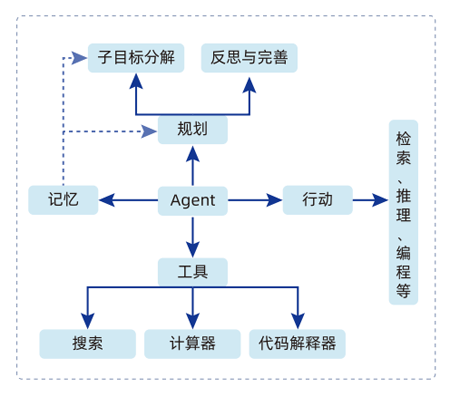
1.大模型Function Call函數調用功能的原理和實現方式
2.開發Function Call實現大模型:實時查詢天氣、訂機票、數據庫查詢等功能
4.解析GPTs和Assistant API的原理及應用方式
5.基于GPTs store和Assistant API開發實用的聊天機器人應用
6.拆解AI Agent的原理及對比與傳統軟件的區別
7.基于CrewAI框架開發自動寫信并發送郵件的AI Agent
客戶服務于支持、個人助理、金融服務、制造業、人力資源
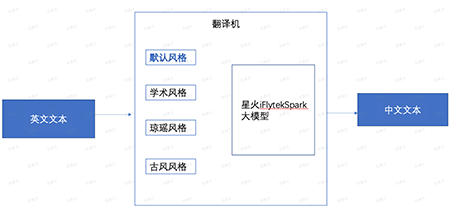
1.多風格翻譯機的介紹、應用場景
2.翻譯機前端界面的搭建:stream、streamlit、websocket
3.星火大模型API的調用方式:key、value
4.翻譯風格的設計:提示詞工程的應用
電子商務平臺、時尚零售、娛樂行業、社交媒體
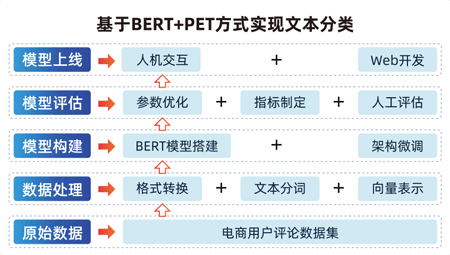
1.準備數據集:正負面新聞標題數據集中包含17149條新聞數據,包括input和target兩個字段
2.上傳數據集:大模型定制訓練平臺
3.模型定制:BLOOMZ-7B是一個由BigScience研發并開源的大型語言模型(LLM),參數量為70億。它是在一個包含46種語言和13種編程語言的1.5萬億個tokens上訓練的,可用于多種自然語言處理任務
4.模型訓練:LoRa、學習率、訓練次數
5.效果評測:提升效果(%)=優化后(正確/已選) - 優化前(正確/已選)
6.模型服務:可使用webAPI的方式進行調用,也可在線體驗服務的應用
創意產業、文學和出版、新聞和媒體、游戲和應用開發

1.虛擬試衣簡介:背景、應用場景、優勢、方法
2.阿里PAI平臺介紹:平臺意義、產品結構、PAI的架構、PAI的注冊與開通
3.PAI-DSW環境搭建:DSW介紹、產品特點、環境搭建方法
4.虛擬試衣實踐:Diffusers、加速器accelerate、下載SD模型、LoRa微調、模型部署、推理驗證
電子商務平臺、時尚零售、娛樂行業、社交媒體

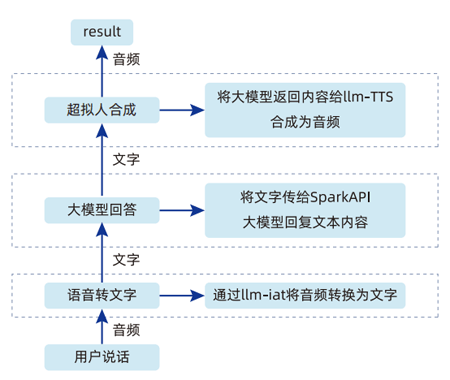
1.語音識別的背景、原理、應用場景
2.語音識別的實現流程:數據預處理+特征的提取+模型構建+模型訓練+模型推理
3.大語言模型的介紹及其在多倫對話中的應用
4.超擬人合成的介紹、原理、應用場景
5.超擬人合成的實現流程:文本預處理(情感分析)+模型選擇+模型訓練+模型推理+語音后處理
客戶服務、健康醫療、虛擬助手、法律咨詢、語言學習和翻譯

沒有工作經驗,期待學習有前景的AI大模型技術
零基礎,對AI人工智能或者大模型感興趣,有想法致力于通過AI人工智能或AI大模型解決實際問題
具備Java、前端、大數據、運維等開發經驗,面臨職場瓶頸期,期待自我提升



碩士,Stable diffusion開發者

人工智能領域技術大佬

哈爾濱工程大學碩士
GIS行業工程實戰大佬

北京化工大學工學碩士
算法專家

多年算法工作經驗
人工智能領域技術大佬
哈爾濱工程大學碩士
GIS行業工程實戰大佬
北京化工大學工學碩士算法專家
多年算法工作經驗
碩士,Stable diffusion開發者


全日制教學管理每天10小時專屬學習計劃
測試、出勤排名公示
早課+課堂+輔導+測試+心理疏導

實戰項目貫穿教學一線大廠實戰項目
實用技術全面覆蓋
課程直擊企業需求

AI教輔保障學習效果水平測評,目標導向學習
隨堂診斷糾錯,階段測評
在線題庫,BI報表數據呈現

個性化就業指導就業指導課,精講面試題
模擬面試,給出就業建議
試用期輔導,幫助平穩過渡

持續助力職場發展免費享,更新項目和學習資料
主題講座,獲取行業前沿資訊
人脈經驗,線下老學員分享會

無憂學就業權益未就業,全額退費
薪資低于標準,發放補貼
多一份安心,學習無憂

課程大綱
基礎班
1. 大模型語言基礎
高手班
1. 大模型語言進階 2. 數據處理與統計分析 3. 機器學習 4. 深度學習基礎 5. NLP自然語言處理基礎 6. 自然語言處理項目1 7. 自然語言處理項目2 8. 大模型開發基礎與項目 9. 企業級大模型平臺開發 10. 圖像分析基礎 11. 多模態大模型項目
人工智能開發 V5.0版本
課時:8天 技術點:60項 測驗:1次 學習方式:線下面授
1.掌握Python開發環境基本配置| 2.掌握運算符.表達式.流程控制語句.數組等的使用| 3.掌握字符串的基本操作| 4.初步建立面向對象的編程思維| 5.熟悉異常捕獲的基本流程及使用方式, 6.掌握類和對象的基本使用方式
1. Python基礎語法零基礎學習Python的開始,包含了以下技術點:
01_變量| 02_標識符和關鍵字| 03_輸入和輸出| 04_數據類型轉換| 05_PEP8編碼規范| 06_比較/關系運算符| 07_if判斷語句語法格式| 08_三目運算符| 09_while語句語法格式| 10_while 循環嵌套| 11_break 和 continue| 12_while 循環案例| 13_for循環
2. Python數據處理掌握Python的數據類型,并對其進行操作處理,包含了以下技術點:
01_字符串定義語法格式| 02_字符串遍歷| 03_下標和切片| 04_字符串常見操作| 05_列表語法格式| 06_列表的遍歷| 07_列表常見操作| 08_列表嵌套| 09_列表推導式| 10_元組語法格式| 11_元組操作| 12_字典語法格式| 13_字典常見操作| 14_字典的遍歷
3. 函數能夠實現Python函數的編寫,包含了以下技術點:
01_函數概念和作用、函數定義、調用| 02_函數的參數| 03_函數的返回值| 04_函數的注釋| 05_函數的嵌套調用| 06_可變和不可變類型| 07_局部變量| 08_全局變量| 09_組包和拆包、引用
4. 文件讀寫能夠使用Python對文件進行操作,包含了以下技術點:
01_文件的打開與關閉、文件的讀寫| 02_文件、目錄操作及案例| 03_os模塊文件與目錄相關操作
5. 異常處理主要介紹了在Python編程中如何處理異常,包含了以下技術點:
01_異常概念| 02_異常捕獲| 03_異常的傳遞
6. 模塊和包主要介紹了Python中的模塊和包的體系,以及如何使用模塊和包,包含了以下技術點:
01_模塊介紹| 02_模塊的導入| 03_包的概念| 04_包的導入| 05_模塊中的__all__ | 06_模塊中__name__
課時:6天 技術點:8項 測驗:1次 學習方式:線下面授
1、掌握面向對象相關技術| 2、知道網絡編程相關知識| 3、掌握數據結構和排序和查找算法
1. 面向對象從逐步建立起面向對象編程思想,再到會使用對象,到創建對象,再到真正理解為什么封裝對象,包含了以下技術點:
01_面向對象介紹| 02_類的定義和對象的創建| 03_添加和獲取對象屬性| 04_self 參數| 05_init方法| 06_繼承| 07_子類方法重寫| 08_類屬性和實例屬性| 09_類方法、實例方法、靜態方法|
2. 網絡編程主要學習通訊協議,以及Python實現TCP、HTTP通訊,包含了以下技術點:
01_IP地址的介紹| 02_端口和端口號的介紹| 03_TCP的介紹| 04_Socket的介紹| 05_TCP網絡應用的開發流程| 06_基于TCP通信程序開發|
3. 多任務編程主要學習Python中多線程、多進程,包含了以下技術點:
01_多任務介紹| 02_多進程的使用| 03_多線程的使用| 04_線程同步|
4. 高級語法主要學習Python的高級語法,包含以下技術點:
01_閉包| 02_裝飾器| 03_正則
5. Python數據結構主要學習主要查找算法、排序算法、關鍵數據結構
01_時間復雜度| 02_線性表| 03_鏈表| 04_常用數據結構 05_二分查找| 06_冒泡、選擇、插入、快排
課時:6天 技術點:105項 測驗:1次 學習方式:線下面授
1.掌握Linux常用命令,為數據開發后續學習打下的良好基礎| 2.掌握MySQL數據庫的使用| 3.掌握SQL語法| 4.掌握使用Python操作數據庫| 5.掌握Pandas案例| 6.知道繪圖庫使用|7.掌握Pandas數據分析項目流程
1. Linux掌握Linux操作系統常用命令和權限管理
01_Linux命令使用| 02_Linux命令選項的使用| 03_遠程登錄| 04_Linux權限管理| 05_vi編輯器使用|
2. MySQL與SQL零基礎小白通過MySQL數據庫,掌握核心必備SQL,包含了以下技術點:
01_數據庫概念和作用| 02_MySQL數據類型| 03_數據完整性和約束| 04_數據庫、表基本操作命令| 05_表數據操作命令| 06_where子句| 07_分組聚合| 08_連接查詢| 09_外鍵的使用| 10_PyMySQL
3. Numpy矩陣運算庫Numpy矩陣運算庫技術,包含以下技術點:
01_Numpy運算優勢,數組的屬性,數組的形狀| 02_Numpy實現數組基本操| 03_Numpy實現數組運算,矩陣乘法
4. Pandas數據清洗Pandas數據清洗技術,包含以下技術點:
1.數據組合:01_Pandas數據組合_concat連接;02_Pandas數據組合_merge數據;03_Pandas數據組合_join| 2.缺失值處理:01_缺失值處理介紹;02_缺失值處理_缺失值數量統計;03_缺失值處理;04_缺失值處理_刪除缺失值;05_缺失值處理_填充缺失值| 3.Pandas數據類型| 4.apply函數:01_Series和DataFrame的apply方法;02_apply使用案例
5. Pandas數據整理Pandas數據處理技術,包含以下技術點:
1.數據分組: 01_單變量分組聚合; 02_通過調用agg進行聚合; 03_分組后transform; 04_transform練習| 2.Pandas透視表: 01_透視表概述&繪員存量增量分析; 02_繪員增量等級分布; 03_增量等級占比分析&整體等級分布; 04_線上線下增量分析| 3.datetime數據類型: 01_日期時間類型介紹; 02_提取日期分組案例; 03_股票數據處理; 04_datarange函數; 05_綜合案例
6. Pandas數據可視化Pandas數據可視化技術,包含以下技術點:
1.Matplotlib可視化| 2.Pandas可視化| 3.Seaborn可視化|
7. Pandas數據分析項目利用所學的Python Pandas,以及可視化技術,完成數據處理項目實戰
RFM客戶分群案例: 01_RFM概念介紹| 02_RFM項目_數據加載和數據處理| 03_RFM項目_RFM計算| 04_RFM項目_RFM可視化| 05_RFM項目_業務解讀和小結|
課時:5天 技術點:80項 測驗:1次 學習方式:線下面授
1.掌握機器學習算法基本原理| 2.掌握使用機器學習模型訓練的基本流程| 3.熟練使用機器學習相關算法進行預測分析
1. 機器學習該部分主要學習機器學習基礎理論,包含以下技術點:
01_人工智能概述| 02_機器學習開發流程和用到的數據介紹| 03_特征工程介紹和小結| 04_機器學習算法分類| 05_機器學習模型評估| 06_數據分析與機器學習
2. K近鄰算法該部分主要學習機器學習KNN算法及實戰,包含以下技術點:
01_K近鄰算法基本原理| 02_K近鄰算法進行分類預測| 03_sklearn實現knn| 04_訓練集測試集劃分| 05_分類算法的評估| 06_歸一化和標準化| 07_超參數搜索| 08_K近鄰算法總結
3. 線性回歸該部分主要學習機器學習線性回歸算法及實戰,包含以下技術點:
01_線性回歸簡介| 02_線性回歸API使用初步| 03_導數回顧| 04_線性回歸的損失函數和優化方法| 05_梯度下降推導| 06_波士頓房價預測案例| 07_欠擬合和過擬合| 08_模型的保存和加載| 09_線性回歸應用-回歸分析
4. 邏輯回歸該部分主要學習機器學習邏輯回歸算法及實戰,包含以下技術點:
01_邏輯回歸簡介| 02_邏輯回歸API應用案例| 03_分類算法評價方法| 04_邏輯回歸應用_分類分析
5. 聚類算法該部分主要學習機器學習聚類算法及實戰,包含以下技術點:
01_聚類算法的概念| 02_聚類算法API的使用| 03_聚類算法實現原理| 04_聚類算法的評估| 05_聚類算法案例
6. 決策樹該部分主要學習機器學習決策樹算法及實戰,包含以下技術點:
01_決策樹算法簡介| 02_決策樹分類原理| 03_特征工程-特征提取| 04_決策樹算法api| 05_決策樹案例
7. 集成學習該部分主要學習機器學習集成算法算法及實戰,包含以下技術點:
01_集成學習算法簡介| 02_Bagging和隨機森林| 03_隨機森林案例| 04_Boosting介紹| 05_GBDT介紹| 06_XGBOOST介紹|
8. 數據挖掘案例數據挖掘案例部分,包含以下技術點:
01_數據探索性分析| 02_特征工程| 03_模型訓練與特征優化| 04_模型部署上線
課時:5天 技術點:60項 測驗:1次 學習方式:線下面授
1.Pytorch工具處理神經網絡涉及的關鍵點|2.掌握神經網絡基礎知識|3.掌握反向傳播原理|3.了解深度學習正則化與算法優化
1. 神經網絡基礎該部分主要學習神經網絡基礎,包含以下技術點:
01_神經網絡基礎:神經網絡的構成、激活函數、損失函數、優化方法及正則化|02_反向傳播原理:梯度下降算法、鏈式法則、反向傳播算法、改善反向傳播算法性能的迭代法|03_深度學習正則化與算法優化:L1、L2、DroupOut、BN、SGD、RMSProp、Adagrad、Adam;04_實現多層神經網絡案例|
2. 深度學習多框架對比該部分主要學習深度學習多框架對比,包含以下技術點:
01_Pytorch| 02_Tensorflow| 03_MxNet| 04_PaddlePaddle|
3. Pytorch框架該部分主要學習Pytorch深度學習框架,包含以下技術點:
01_Pytorch介紹|02_張量概念|03_張量運算|04_反向傳播|05_梯度,自動梯度|06_參數更新|07_數據加載器|08_迭代數據集|
課時:10天 技術點:100項 測驗:1次 學習方式:線下面授
1.掌握NLP領域前沿的技術解決方案|2.了解NLP應用場景|3.掌握NLP相關知識的原理和實現|4.掌握傳統序列模型的基本原理和使用|5.掌握非序列模型解決文本問題的原理和方案|6.能夠使用Pytorch搭建神經網絡|7.構建基本的文本分類器模型|8.使用fasttext進行快速的文本分類|9.為后續NLP項目學習奠定基礎,能夠勝任多數企業的NLP工程師的職位
1. NLP入門該部分主要學習NLP基礎,包含以下技術點:
01_NLP簡介|02_NLU簡介|03_文本生成簡介|04_機器翻譯簡介|05_智能客服介紹|06_機器人寫作介紹|07_作文打分介紹
2. 文本預處理該部分主要學習文本預處理技術,包含以下技術點:
01_文本處理的基本方|02_文本張量表示方法|03_文本語料的數據分析,文本特征處理,數據增強方法|04_分詞,詞性標注,命名實體識別|05_one-hot編碼,Word2vec,Word Embedding|06_標簽數量分布,句子長度分布,詞頻統計與關鍵詞詞云
3. RNN及變體該部分主要學習RNN、LSTM、GRU等技術,包含以下技術點:
01_傳統RNN,LSTM,Bi-LSTM,GRU,Bi-GRU|02_新聞分類案例,機器翻譯案例|03_seq2seq,遺忘門,輸入門,細胞狀態,輸出門,更新門,重置門
4. Transformer原理該部分主要學習Transformer技術,包含以下技術點:
01_輸入部分,輸出部分,編碼器部分,解碼器部分,線性層|02_softmax層,注意力機制,多頭注意力機制|03_前饋全連接層,規范化層,子層連接結構,語言模型|04_wikiText-2數據集,模型超參數|05_模型的訓練,模型驗證
5. 遷移學習該部分主要學習遷移學習,包含以下技術點:
01_fasttext工具,進行文本分類|02_CBOW模式,skip-gram模式,預訓練模型|03_微調,微調腳本,訓練詞向量|04_模型調優|05_n-gram特征|06_CoLA 數據集,SST-2 數據集,MRPC 數據集|07_BERT|08_pytorch.hub
課時:6天技術點:80項測驗:0次學習方式:線下面授
以投滿分項目為例:1. 基于大規模業務留存數據構建快速文本分類系統|2. 基于推薦系統內部分頻道投遞的需求, 快速搭建短文本精準分類投遞的模型|3. 基于隨機森林和FastText搭建快速基線模型, 驗證業務通道的能力. | 4. 基于BERT的遷移學習優化模型搭建的能力. | 5. 實現神經網絡量化的優化與測試. | 6. 實現神經網絡剪枝的優化與測試. | 7. 實現神經網絡知識蒸餾的優化與測試. | 8. 更多主流預訓練模型的優化與深度模型剖析| 9. BERT模型在生成式任務和工程優化上的深入擴展

投滿分項目主要解決在海量新聞,咨詢等文本信息的場景下, 需要完成文本類別的快速鑒別與分類, 并完成按頻道的投遞和排隊, 最終推薦給對該類別感興趣的用戶, 從而提升點擊量,閱讀量,付費量等關鍵指標. 該項目結合今日頭條真實場景下的海量數據, 快速搭建隨機森林和FastText的基線模型, 以驗證商業化落地的可行性. 更多聚焦在深度學習的優化方法上, 搭建基于BERT的初版微調模型, 應用量化,剪枝,預訓練模型微調,知識蒸餾等多種手段,反復迭代,反復優化模型的離線效果,在線效果.
1.海量文本快速分類基線模型解決方案| 2.基于預訓練模型優化的解決方案| 3.模型量化優化的解決方案| 4.模型剪枝優化的解決方案| 5.模型知識蒸餾優化的解決方案| 6.主流遷移學習模型微調優化的解決方案
1. 項目背景介紹, 項目快速實現基于隨機森林的基線模型1.0, 和基于FastText的基線模型2.0 2. 遷移學習優化, 實現基于BERT的遷移學習模型搭建和訓練, 并對比模型關鍵指標的提升. 3. 模型的量化, 實現對大型預訓練模型的量化, 并對比原始模型與量化模型的差異. 4. 模型的剪枝, 實現對模型的剪枝的操作, 包含主流的對特定網絡模塊的剪枝, 多參數模塊的剪枝, 全局剪枝, 用戶自定義剪枝, 包含處理細節和理論知識. 5. 遷移學習微調, 包含BERT模型微調. 6. 模型的知識蒸餾, 詳細解析知識蒸餾的原理和意義, 并實現知識蒸餾模型的搭建, 對比知識蒸餾后的新模型的優異表現, 并做詳細的對比測試.
課時:6天技術點:80項測驗:0次學習方式:線下面授
以泛娛樂關系抽取為主:1、理解關系抽取任務 2、了解實現關系抽取任務的基本方法 3、掌握Casrel模型架構及工作原理 4、掌握關系抽取數據處理方法 5、掌握關系抽取的應用場景

該項目基于泛娛樂數據場景,依賴NLP技術從文本中提取實體和它們之間的關系,旨在輔助企業構建知識圖譜。關系抽取的實現主要包括3種方法:分別是基于規則、Pipeline流水線、Joint聯合抽取等。其中基于規則的方法由人工設定模版,完成簡單關系的任務抽取;基于Pipeline流水線方法則是在完成實體識別的前提下,利用BILSTM+Attention模型實現關系分類,相比規則,該方法具備關系推理的能力;在Joint聯合抽取方法應用方面,實現了可以解決多元復雜關系抽取問題的Casrel模型搭建。在實現關系抽取的基礎之上,基于Neo4j圖數據庫,應用Cypher語言完成知識的存儲。整個項目全方位為大家展現不同關系抽取方法的優缺點以及應用場景,目地讓學生學會在不同場景下,選擇合適的方法解決對應問題,且最終通過圖譜的形式展示業務的實際應用。
1.文本數據處理解決方案| 2.基于Casrel模型實現關系抽取的解決方案
1.項目介紹:理解關系抽取任務以及關系抽取的常見場景 2. 環境構建:項目開發所需搭建的環境 3. 數據集介紹:數據來源、獲取方式以及存儲方式介紹 4. 數據處理:構建DataSet以及Dataloader 5. Casrel模型構建:實現關系抽取
課時:12天技術點:100項測驗:1次學習方式:線下面授
以物流信息咨詢智能問答項目: 1.掌握LangChain工具的基本使用方法,了解如何通過LangChain構建和管理語言模型應用。 2.熟悉ChatGLM-6B模型的應用,了解如何將大語言模型與本地知識庫結合,實現高效準確的問答功能。 3.理解向量知識庫的基本概念和技術原理,掌握如何構建和使用向量知識庫來存儲和檢索知識信息。 4.掌握知識庫的構建方法,從數據采集、處理到存儲,學習如何將電商物流相關信息整合到知識庫中。 5.理解RAG系統的基本原理和實現方法,學習如何結合檢索和生成技術,提升問答系統的準確性和實用性。 6.從零開始搭建一個問答機器人,掌握整個系統的設計、實現和部署過程。

項目基于LangChain+ChatGLM-6B實現電商物流 本地知識庫問答機器人搭建,讓模型根據本地信 息進行準確回答,解決大模型的“幻覺”問題, 實現精準問答。通過項目皆在掌握LangChain工 具的基本使用方式,理解向量知識庫以及實現知 識庫的技術原理,快速構建檢索增強生成 (RAG)系統
1.LangChain工具使用介紹解決方案 2.ChatGLM-6B模型集成到問答系統中的解決方案 3.向量知識庫的構建和檢索的解決方案 4.搭建RAG系統的解決方案
1.項目介紹:理解什么是RAG系統 2.項目流程梳理(從本地知識庫搭建,到知識檢索,模型生成答案等流程介紹) 3.數據預處理:本地文檔知識分割,向量,存儲 4.LangChain框架的詳解講解:6大組件應用原理和實現方法 5.基于本地大模型ChatGLM-6B封裝到LangChain框架中 6.實現LangChain+ChatGLM-6B模型的知識問答系統搭建
課時:6天技術點:80項測驗:0次學習方式:線下面授
以基于StableDiffusion的圖像生成項目為例:1.了解虛擬試衣的背景 2.知道阿里PAI平臺的使用方式 3.能夠搭建虛擬試衣的環境 4.能夠完成虛擬試衣的實踐并進行資源清理

利用計算機視覺技術,上傳照片,選擇不同的服裝進行試穿,使得用戶無需到實體店,就能夠在線上體驗不同的風格,更方便地進行購物決策。該項目利用人體數據、服裝圖像和文本提示,擴 散模型Diffusion Model在人體數據和服裝圖像的控制因子下,分別處理文本提示,最后進行信息的融合,實現逼真的試衣效果。
虛擬試衣的常見解決方案 阿里PAI平臺使用的解決方案 PAI—DSW環境搭建的解決方案 虛擬試衣實踐的解決方案
1.虛擬試衣簡介:背景,應用場景,優勢,方法 2.阿里PAI平臺:介紹,平臺意義,產品結構,PAI的架構,PAI的注冊與開通 3.PAI-DSW環境搭建:DSW介紹,產品特點,環境搭建方法 4.虛擬試衣實踐:Diffusers,加速器accelerate,下載SD模型,Lora微調,模型部署,推理驗證
課時:5天 技術點:100項 測驗:1次 學習方式:線下面授
1.熟悉深度學習主要及前沿網絡模型的架構原理及在實際業務場景中的應用|2.掌握深度學習在計算機視覺中的應用,包括但不限于分割檢測識別等等,3.掌握實際工作中深度學習的具體流程,數據及標注處理,建模訓練,及模型部署應用等。|4.可勝任深度學習算法工程師,圖像與計算機視覺算法工程師等,并持續優化與迭代算法
1. 圖像與視覺處理介紹該模塊主要介紹計算機視覺的定義,發展歷史及應用場景
01_計算機視覺定義、計算機視覺發展歷史|02_計算機視覺技術和應用場景、計算機視覺知識樹和幾大任務
2. 圖像分析該部分主要學習圖像分析的相關內容:
01_圖像的表示方法;| 02_圖像的幾何變換;| 03_顏色變換;| 04_mixup;| 05_copypaste|
3. 圖像分類該部分主要學習圖像分類的相關知識:
01_分類的思想;| 02_經典網絡結構;AlexNet;| 03_InceptionNet;| 04_ResNet;| 05_模型微調策略|
4. 圖像分割該部分主要介紹圖像分割的內容:
01_分割思想| 02_Unet;| 03_FCN Net;| 04_MaskRCNN|
課時:6天技術點:40項測驗:0次學習方式:線下面授
以虛擬試衣項目為例: 1.知道AIGC是什么,理解AIGC的產品形態 2.知道圖像生成的常用方式 3.理解GAN ,VAE,Diffusion的思想 4.掌握Stable Diffusion的網絡結構 5.理解文圖匹配的clip模型 6.理解Unet網絡和采樣算法的作用 7.知道VAE解碼器的作用 8.知道dreambooth和LoRA的模型訓練方式 9.能夠搭建圖像生成的小程序
基于Stable Diffusion的圖像生成項目是一種基于深度學習的圖像生成方法,旨在生成高質量、逼真的圖像。該項目利用穩定擴散過程,通過逐漸模糊和清晰化圖像來實現圖像生成的過程。這種方法在圖像生成領域具有廣泛的應用,包括藝術創作、虛擬場景生成、數據增強等。
圖像生成的常見解決方案 文圖匹配的解決方案 擴散模型噪聲去除的解決方案 潛在空間擴散模型的解決方案 擴散模型訓練的解決方案 小程序搭建的解決方案
1.AIGC的詳解:AIGC簡介,類型,應用場景,產品形態 2.圖像生成算法:GAN; VAE ;Diffusion; DALLe; imagen 3.StableDiffusion的詳解:Diffusion,latent diffusion ;satble diffusion 4.stablediffusion實踐: 模型構建,模型訓練,lora,dreambooth,圖像生成效果 5.圖像生成小程序搭建: 基于stablediffusion構建圖像生成的小程序
課程名稱:主要針對:主要使用開發工具:
課程名稱
人工智能AI進階班/AI大模型開發
課程推出時間
2024.06.06
課程版本號
5.0
主要使用開發工具
PyCharm、DataGrip、Jupyter NoteBook
課程介紹
人工智能開發V5.0課程體系升級以企業需求為導向,專為培養和打造高級人工智能工程師、高含金量課程重磅推出,以業務為核心驅動項目開發,課程包括機器學習和深度學習框架Scikit-Learn和Pytorch,能夠解決企業級數據挖掘、NLP自然語言處理、大模型開發與CV計算機視覺實際問題,通過理論和真實項目相結合,讓學生能夠掌握人工智能核心技術和應用場景。并推出「六項目制」項目教學,通過六個不同類型和開發深度的項目,使學員能夠全面面對大部分企業人工智能應用場景。大型項目庫,多行業多領域人工智能項目課程,主流行業全覆蓋,其中項目課程包括了多行業13個場景的項目課程,讓學生達到大廠的項目經驗要求。課程消化吸收方面:V5.0在V4.0版本基礎上迭代更新,加大了大模型開發比例,同時注重專業課的消化吸收,降低學習難度,提升就業質量。
全新升級四大課程優勢,助力IT職業教育行業變革:
優勢1:熱門崗位全覆蓋,匹配企業崗位需求,拓寬職業選擇,實現階段目標;優勢2:與大廠合作,共建大模型課程,助力掌握前沿技術,增強就業競爭力;優勢3:定制垂直領域大模型,專項領域賦能,打造就業薪資高,就業速度快的AI大模型人才;優勢4:覆蓋NLP,CV完整解決方案和技術棧,解決多業務場景問題。
1
更新Pytorch2.3.0
1
新增星火語音大模型
1
新增基于訊飛大模型定制平臺的財經新聞情感分析項目
1
新增多風格英譯漢翻譯機項目
1
新增虛擬試衣項目
1
新增基于StableDiffusion的圖像生成項目
1
新增大模型AI Agent開發應用
1
新增新零售行業評價決策系統
1
新增大模型搭建醫療問診機器人
1
新增物流信息咨詢智能問答項目
1
新增微博文本信息抽取項目
1
新增泛娛數據關系抽取項目
1
新增多模態技術及項目
1
友情提示更多學習視頻+資料+源碼,請加QQ:2632311208。
課程名稱
人工智能AI進階班
課程推出時間
2023.02.24
課程版本號
4.0
主要使用開發工具
Linux+PyCharm+Scikit-Learn+Pytorch+Neo4j+Docker
主要培養目標
以數據挖掘和NLP自然語言處理為核心方向,培養企業應用型高精尖AI人才
課程介紹
人工智能開發V4.0課程體系升級以企業需求為導向,專為培養和打造高級人工智能工程師、高含金量課程重磅推出,以業務為核心驅動項目開發,課程包括機器學習和深度學習框架Scikit-Learn和Pytorch,能夠解決企業級數據挖掘、NLP自然語言處理與CV計算機視覺實際問題,通過理論和真實項目相結合,讓學生能夠掌握人工智能核心技術和應用場景。并推出「六項目制」項目教學,通過六個不同類型和開發深度的項目,使學員能夠全面面對大部分企業人工智能應用場景。大型項目庫,多行業多領域人工智能項目課程,主流行業全覆蓋,其中項目課程包括了多行業13個場景的項目課程,讓學生達到大廠的項目經驗要求。課程消化吸收方面:V4.0在V3.0版本基礎上迭代更新,注重專業課的消化吸收,降低學習難度,提升就業質量。
1
優化Python系統編程,針對人工智能必須的Python高階知識體系重構課程,增加基礎數據結構內容
1
新增機器學習部分[數據挖掘項目實戰],以多場景業務為背景,通過SQL和Pandas完成數據處理與統計分析,夯實使用機器學習解決數據挖掘問題能力。
1
新增NLP方向[知識圖譜項目],基于知識圖譜的多功能問答機器人項目, 主要解決當前NLP領域中大規模知識圖譜構建的問題和圖譜落地的問題.知識圖譜的構建主要分為知識構建和知識存儲兩大子系統. 包括知識構建, 知識存儲, 知識表達, 路由分發, 結果融合等實現.最終呈現一個基于知識圖譜的問答機器人。
新增[知識抽取項目],該項目針對于泛娛樂場景下復雜業務關系進行實體抽取,幫助企業構建知識圖譜。
1
優化NLP方向[NLP基礎課程]:修改文本數據增強方法,解決原始谷歌接口被限制調用的問題;優化Seq2Seq英譯法案例,修改原始代碼bug,提升模型的準確率;新增FastText模型架構介紹;加深FastText模型處理分類的問題的原理理解;新增Word2Vec訓練兩種優化策略,加速模型快速收斂。
1
優化計算機視覺CV基礎:圖像分類的經典網絡,開山之作ALexNet,VGGNet,GoogLenNet,ResNeT,ResNetV2,VGGRep,SeNet,輕量型網絡:mobileNet,shuffleNet,EfficientNet,模型微調,數據增強,cutmix,copypaste,mosaic,目標檢測任務,IOU,Map,正負樣本設計,smoothL1損失,RCNN系列網絡架構:RCNN,FastRCNN,FasterRCNN,MaskRCNN,FPN結構,ROIpooling設計,anchor思想,RoiAlign設計,訓練策略;yolo系列網絡V1-V8:DarkNet,yolo-FPN特征融合,passthrough融合方法,多尺度訓練,IOU系列損失,DIOU,CIOU,SIOU等,輸出端的解耦,REP-PAN結構,E-ELAN結構,預測階段的BN設計,SPP和SPPF結構
1
優化智慧交通項目:目標跟蹤方法,運動模型的設計,DBT和DFT初始化方法,JIT的加速方法,yoloV7目標檢測,REP的使用,檢測輔助端的使用,E-ELAN的使用,backbone的實現,head結構的實現,數據分析,數據預處理,數據增強,模型訓練,預測與評估,車輛檢測,kalman的使用,預測和更新階段,KM算法的匹配,匈牙利算法,IOU匹配,級聯匹配,ReId特征提取,歐式距離,余弦距離,馬氏距離計算,目標狀態更新,Deepsort算法目標跟蹤,代價矩陣的設計,虛擬線圈的設計,線圈位置的獲取,雙線圈檢測車流量支持mac電腦的m1芯片和m2芯片的學習
課程名稱
人工智能AI進階班
課程推出時間
2022.01.20
課程版本號
3.0
主要培養目標
以機器學習和深度學習技術,培養企業應用型高精尖AI人才
主要使用開發工具
Linux+PyCharm+DataSpell+Pytorch+Tensorflow+Neo4j+Docer+k8s
課程介紹
人工智能V3.0課程體系升級以企業需求為導向,專為培養和打造高級人工智能工程師、高含金量課程重磅推出,以業務為核心驅動項目開發,課程包括機器學習和深度學習框架Pytorch和TensorFlow,能夠解決企業級數據挖掘、NLP自然語言處理與CV計算機視覺實際問題,通過理論和真實項目相結合,讓學生能夠掌握人工智能核心技術和應用場景。并推出「六項目制」項目教學,通過六個不同類型和開發深度的項目,使學員能夠全面面對大部分企業人工智能應用場景。大型項目庫,多行業多領域人工智能項目課程,主流行業全覆蓋,其中項目課程天數占比為100天,包括了多行業13個場景的項目課程,讓學生達到大廠的項目經驗要求。課程消化吸收方面:V3.0在V2.0版本基礎上迭代更新,注重專業課的消化吸收,降低學習難度,提升就業質量。
1
優化優化Python系統編程,針對人工智能必須的Python高階知識體系重構課程
1
新增[數據處理與統計分析階段],以Linux為基礎,通過SQL和Pandas完成數據處理與統計分析,為人工智能數據處理奠定技術基礎。
1
優化優化機器學習算法,每個算法都兼具使用場景,數學推導過程及參數調優
1
新增[機器學習與多場景],增加多場景案例實戰,包括用戶畫像,電商運營建模等多場景案例實戰
1
新增數據挖掘方向[百京金融風控]項目,從反欺詐、信用風險策略、評分卡模型構建等熱點知識,使得學員具備中高級金融風控分析師能力。
1
新增數據挖掘方向[萬米推薦系統]項目,從多數據源采集、多路召回、基于機器學習算法粗排算法與基于深度學習精排,解決了在大數據場景下如何實現完整推薦系統,使得學員可以具備企業級推薦項目開發能力。
1
優化深度學習基礎課由TensorFlow切換為Pytorch,面向零基礎同學更加友好
1
優化NLP基礎課程Transform基礎和Attention注意力機制在原理之后增加英譯漢的案例,加強學生對基礎算法原理的理解
1
優化NLP基礎課程遷移學習API版本變化問題,優化傳統序列模型算法原理
1
新增NLP方向[蜂窩頭條文本分類優化]項目,增強學生NLP算法優化方面技能
1
新增NLP方向[知識圖譜]項目,通過本體建模,知識抽取,知識融合,知識推理,知識存儲與知識應用方面,學生可以掌握完整知識圖譜構建流程。
1
新增[面試加強課]通過鞏固機器學習與深度學習基礎算法,加強核心算法掌握,增加數據結構基礎算法、動態規劃算法、貪心算法等面試高頻算法題,加強多行業人工智能案例理解與剖析
1
刪除Ubuntu環境搭建開發環境
課程名稱
人工智能AI進階班
課程推出時間
2021.02.01
課程版本號
2.0
主要針對
python3 & python2
主要使用開發工具
linux+PyCharm+Pytorch+Tensorflow+OpenCV+neo4j+Docer+k8s
課程介紹
AI理論方面: 通過新的開發的文本摘要項目、傳智大腦項目, 提升學員復雜模型訓練和優化的能力。
AI工程化方面: 新增的算法工程化講座, 直接面向一線公司實際開發場景和需求, 比如服務日志, A/B測試, Git提交, Docker, K8S部署等, 讓學員親臨公司場景, 求職后更好的無縫銜接進企業級開發。
AI新熱點和趨勢: 通過增加量化、剪枝、知識蒸餾、遷移學習等一線優化技術, 讓學生有更多處理問題的武器和思路;增加知識圖譜熱點、mmlab框架熱點、YOLO1~5算法系列,能更好的匹配業界需求。
課程消化吸收方面:V2.0在V.1.x版本基礎上迭代更新,注重專業課的消化吸收,降低學習難度,提升就業速度、就業質量。
1
新增NLP方向【文本摘要項目】:自動完成文本信息的主題提取,中心思想提取,可以類比京東,當當網的商品自動宣傳文案;快速的將主要信息展示給用戶, 廣泛應用于財經, 體育, 電商, 醫療, 法律等領域。基于seq2seq + attention的優化模型,基于PGN + attention + coverage的優化模型,基于PGN + beam-search的優化模型,文本的ROUGE評估方案和代碼實現:weight-tying的優化策略、scheduled sampling的優化策略。
1
新增AI基礎設置類項目【傳智大腦】,目前提供AI前端功能展示、AI后端模型部署、AI在線服務、AI模型訓練功能等系統功能。AI開發服務提供了信息中心網咨輔助系統,文本分類系統、考試中心試卷自動批閱系統、CV統計全國開班人數等系統;綜合NLP、CV和未來技術熱點。
1
新增CV方向【人流量統計項目】:以特定商場、客服場景對人流量進行分析和統計。掌握mmlab框架、核心模塊MMDetection;resnet骨架網絡特征提取,SSD網絡和Cascade R-CNN網絡目標檢測;利用剪枝,壓縮和蒸餾等方法減小模型規模;完成前后端部署(Flask + Gunicorn)、模型部署(ONNX-runtime技術)。
1
優化NLP方向【AI在線醫生項目】: 兩個離線模型 (命名實體審核模型, 命名實體識別模型)的優化,提升準確率, 召回率,F1的效果。 一個在線模型 (句子主題相關模型)的優化, 重在量化, 壓縮, 知識蒸餾, 提升處理速度并展示對比測試實驗。
1
新增知識圖譜熱點案例:知識圖譜編程、深化neo4j中的cypher代碼, 相關案例。
1
新增計算機視覺目標檢測熱點算法YoLov1~v5 V1~V5模型的網絡架構、輸入輸出、訓練樣本構建,損失函數設計;模型間的改進方法;多尺度檢測方法、先驗框設計;數據增強方法、多種網絡架構及設計不同模型的方法。
1
優化計算機視覺專業課:RCNN系列網絡進階課程:FasterRCNN目標檢測的思想,anchor(錨框)設計與實現,掌握RPN網絡是如何進行候選區域的生成的,掌握ROIPooling的使用方法掌握fasterRCNN的訓練方法,掌握RCNN網絡的預測方法。
1
新增AI算法工程化專題:10個子案例展示算法工程化中的實際工程問題, 企業真實開發中的問題和解決方案。研發, 測試環境的異同, 服務日志的介紹和實現, A/B測試,模型服務風險監控,在線服務重要指標,Git提交與代碼規范化,正式環境部署(Docker, K8S),,數據分析與反饋。
課程名稱
人工智能AI進階班
課程推出時間
2020.6.1
課程版本號
1.5
主要針對版本
python3 & python2
主要使用開發工具
linux+PyCharm+Pytorch+Tensorflow
課程介紹
以周為單位迭代更新課程,包括機器學習、自然語言處理NLP、計算機視覺、AI算法強化等課程。同時為了更好的滿足人工智能學員更快速的適應市場要求,推出了自然語言處理NLP案例庫、計算機視覺CV案例庫、面試強化題等等。同時也增加職業拓展課,學生學習完AI課程以后,可在職學習:推薦系統、爬蟲、泛人工智能數據分析。
1
新增計算機視覺CV案例庫
1
新增自然語言處理案例庫
1
新增AI企業面試題
1
新增算法強化課程
1
新增計算機視覺強化課
課程名稱
人工智能AI進階班
課程推出時間
2019.12.21
課程版本號
1.0
主要針對版本
Python3 & Python2
主要使用開發工具
linux+PyCharm+Pytorch+Tensorflow
課程介紹
人工智能賦能實體產業的規模以每年40%的速度遞增,人工智能人才在計算機視覺CV、自然語言處理NLP、數據科學的推薦廣告搜索的需求越來越明確。傳智教育研究院經過2年潛心研發,萃取百余位同行經驗,推出全新的人工智能1.0課程。全新的人工智能課程體系具有以下優勢:
1)六個月高級軟件工程師培訓課程。精準定位、因材施教,人工智能和Python開發分成兩個不同的班型進行授課。
2)理論+實踐培養AI專精型人才。如何培養人才達到企業的用人標準?傳智教育提出了課程研發標準:1、AI理論方面,培養學員AI算法研究能力:AI算法實用性、先進性、可拓展性;2、AI實踐方面,培養學員利用AI理論解決企業業務流的能力。
3)多領域多行業項目,全生態任性就業。設計多領域多行業項目有:智能交通項目(CV)、 實時人臉檢測項目(CV)、在線AI醫生項目(NLP)、智能文本分類項目(NLP)、泛娛樂推薦項目(CV+推薦)、CT圖像肺結節自動檢測項目(CV)、小智同學-聊天機器人(NLP)、場景識別項目(CV)、在線圖片識別-商品檢測項目(CV)、黑馬頭條推薦系統(推薦+數據科學)。
4)AI職業全技能(NLP、CV、數據科學-推薦廣告搜索),涵蓋8大主流就業崗位。視覺處理工程師(CV)、自然語言處理工程師(NLP)、推薦系統工程師、機器學習工程師、深度學習工程師、數據分析工程師、數據挖掘工程師、知識圖譜工程師。
5)課程設置科學合理,適合AI技術初學者。
6)技術大牛傾力研發,專職沉淀AI新技術。
1
新增機器學習進階課程
1
新增計算機視覺項目:實時人臉檢測項目、智能交通項目
1
新增自然語言處理NLP項目:在線AI醫生項目、智能文本分類項目
1
新增算法強化課程:進化學習、分布式機器學習、數據結構強化
教師錄取率<3%,從源頭把控師資,帶你過關斬將掌握每一個知識點< /p>
用數據驅動教學,貫通教/學/練/測/評,為每一位學員私人定制學習計劃和就業服務








學前入學多維測評
學前目標導向式學習
學中隨堂診斷糾錯
學中階段效果測評
學后在線作業試題庫
學后問答社區查漏補缺
保障BI報表數據呈現
就業面試指導就業分析
就業流程
全信息化處理
學員能力
雷達圖分析
定制個性化
就業服務
技術面試題
講解
就業指導課
面試項目分析
HR面試攻略
模擬企業
真實面試
專業簡歷指導
面試復盤輔導
風險預警
企業黑名單提醒
老學員畢業后即可加入傳智匯精英社區,持續助力學員職場發展

傳智教育旗下IT互聯網精英社區,以匯聚互聯網前沿技術為核心,以傳遞、分享為己任,聯合經緯創投、創新工場、京東人工智能、華為等眾多關注互聯網的知名機構及企業、行業大咖,共同研究中國互聯網深度融合、跨界滲透、整合匯聚、相互促進的信息化資源共享平臺。
行業沙龍

高端人脈

職場資源

技術研習

查看其他班級
9970元/月平均薪資
15900元/月最高薪資
100%就業率
58人月薪過萬
*學員就業信息統計數據為數據庫中實時調取的真實相關數據,非廣告宣傳
聯系我們關于黑馬1024程序員節
學習工具免費公開課免費視頻下載
報名流程校區分布住宿環境

黑馬程序員公眾號

黑馬程序員小程序

江蘇傳智播客教育科技股份有限公司 版權所有Copyright 2006-2024, All Rights Reserved 蘇ICP備16007882號 營業執照 增值電信業務經營許可證 出版物經營許可證  蘇公網安備 32132202000574號
蘇公網安備 32132202000574號

| 武鸣县 | 松滋市 | 广南县 | 寻甸 | 平乐县 | 株洲市 |
| 师宗县 | 禄劝 | 岑溪市 | 塘沽区 | 新津县 | 枣庄市 |
| 江都市 | 婺源县 | 体育 | 宝清县 | 峨眉山市 | 梧州市 |














